March 2024, no. 139













Create a MARIN account to stay updated


Eelco Frickel,
Team leader Time domain simulation & Data science




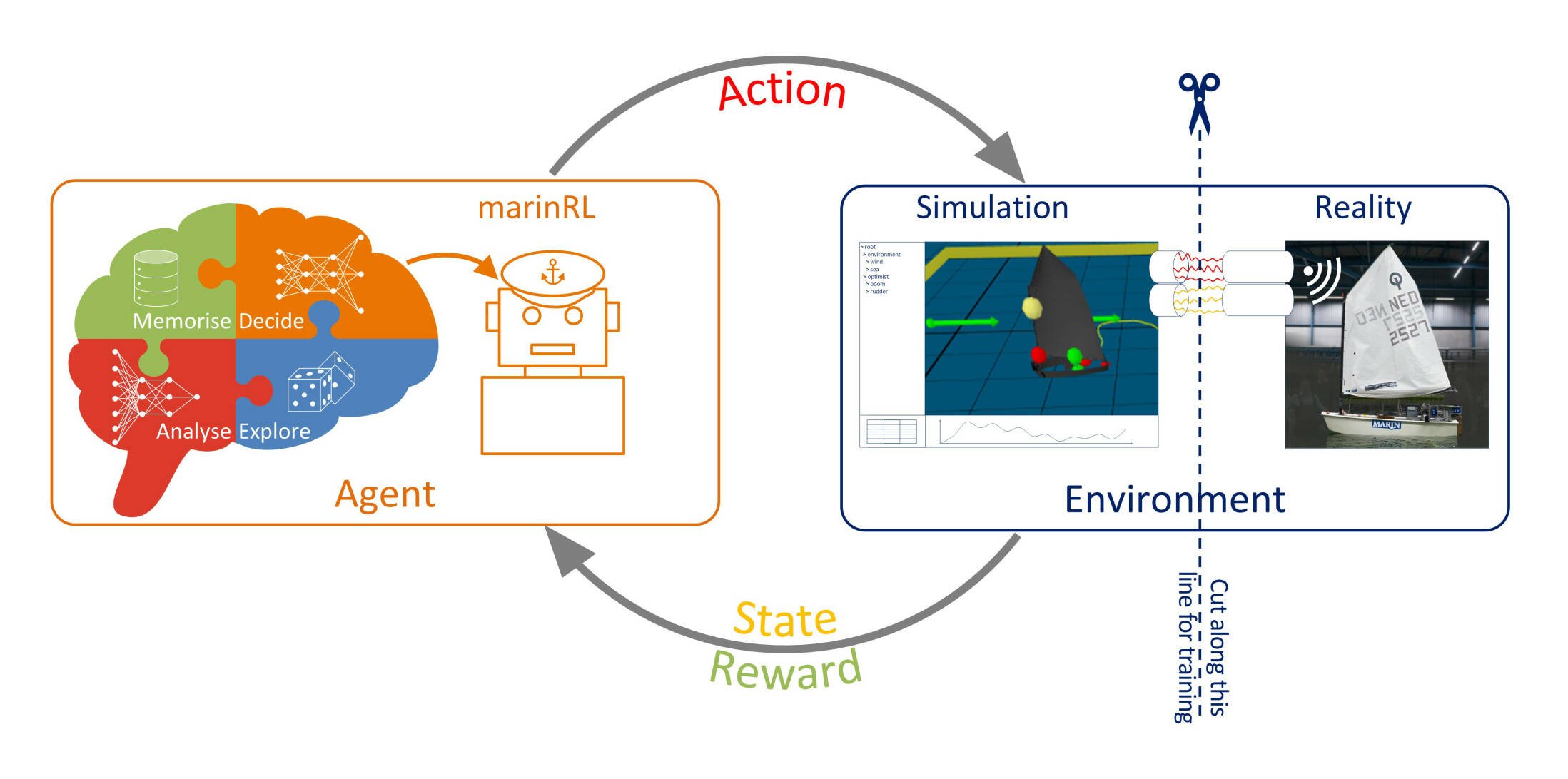
Figure 1: Connection between the AI agent and its environment. The agent does not need to know if it is dealing with a simulation or a physical environment. It sends the selected actions to the environment and receives an updated state back and intermediate feedback, thus building experience with the long-term results of actions.
Report
Put a child in an Optimist and it will learn how to sail intuitively, without understanding the details of aerodynamics and hydrodynamics. This inspired MARIN’s AI Sail Team to take up a challenge: can a computer learn to do the same with the help of AI? November 2023 was the moment of truth, during a demonstration in our Offshore Basin.
The background of this challenge is an important one: what can artificial intelligence and machine learning contribute to a cleaner, smarter and safer maritime world? Most maritime prediction methods are founded on a model-based approach: physics-based models are combined in a computational model and validated in tests and reality. With AI Sail we want to demonstrate the possibilities of data-driven methods, where the physics are not explicit in the model, but implicit in the data. In simple terms: if children can learn how to sail an Optimist without knowledge of aerodynamics, hydrodynamics and oceanography, an AI algorithm should be able to do the same. For a cleaner, smarter and safer maritime world, this means that predictive models or decision support systems can be brought to challenges where explicit modelling is not (fully) possible or desirable.


Risky behaviour
Full control also means that risky behaviour can emerge. Without limiting the actions the AI can explore, undesirable behaviour can be avoided by giving proper feedback on this behaviour. This often requires the introduction of terms in the reward function that do not directly relate to the objective but serve as implicit instructions on what not to do. RL will find a balance between reaching the objective quickly and the perceived costs of the actions chosen. It might be tempting to introduce terms that describe what to do as well, but this is often too restrictive and limits exploration to find optimal actions.
For this project a Reinforcement Learning (RL) agent was used, which learns to optimise decision processes through interactions with a dynamic environment. The optimisation is guided by so-called rewards that are given based on the current performance. The rewards mimic the sense of accomplishment when a challenging task is completed, or getting closer to completion, and reinforce the actions taken that lead to the result. Negative rewards, or penalties, can also serve as a reminder of what not to do when things go wrong. An important aspect of the RL algorithms is that they do not just connect the reward to the last actions, but rather to the series of actions that lead to a result. This is where RL differs the most from supervised learning: there is no prescribed relation between the state of the vessel and the action that needs to be taken in that state. Giving the correct feedback through rewards is not straightforward though and is often the main challenge of RL.
The AI Sail Team consists of a broad mix of MARIN specialists including experts in AI/machine learning, time domain simulations, software engineering, sailing/wind assist and (wireless) model testing. This allowed a full-stack approach, such that AI models could be developed and pre-trained in a well-tuned simulation environment before seamlessly transitioning to the physical tests in our Offshore Basin. Being able to effortlessly combine the simulated and physical setups is invaluable for efficient development of solutions and early evaluation.
Demonstration in MARIN’s Offshore Basin.
Hannes Bogaert,
Leader AI Sail Team

Explanation of Reinforcement Learning by Fanny Rebiffé, as applied in the AI Sail project.
A number of agents were trained, with different choices for RL algorithms, reward functions and other settings. It was interesting to see the different behaviours that they showed: one agent did some tacks, with some sculling at the end to quickly reach the target with a minimum of penalties for cheating; one agent was quick, but a bit more risky; one agent was conservative, but still rather efficient; one agent was a bit too conservative and not always successful. This reminds us of the difference in temperament and choices made by children who learn to sail. They are not all the same and show qualities in different departments.
For the future, we see much potential for generalisation - one of the strong suits of machine learning - where a single model is trained to work in many different situations, irrespective of what ship or operational conditions it is presented with. Data from many ships and voyages can be used, benefitting all participants, for example for fuel efficiency or detection of performance degradation. Operational advice can even be based on examples from the experts on board, from which RL can extract the best aspects of all and even learn to prevent mistakes.
The algorithm was given full control of rudder, sheet and a traversing mass and the task was to sail upwind. Within the square domain the vessel could sail in, a couple of tacks was needed to reach the other side of the basin. However, with full control, some cheating is possible as well, for example by sculling: using rudder oscillations to propel the boat.
More info




Demonstration in MARIN’s Offshore Basin.
More info
A number of agents were trained, with different choices for RL algorithms, reward functions and other settings. It was interesting to see the different behaviours that they showed: one agent did some tacks, with some sculling at the end to quickly reach the target with a minimum of penalties for cheating; one agent was quick, but a bit more risky; one agent was conservative, but still rather efficient; one agent was a bit too conservative and not always successful. This reminds us of the difference in temperament and choices made by children who learn to sail. They are not all the same and show qualities in different departments.
For the future, we see much potential for generalisation - one of the strong suits of machine learning - where a single model is trained to work in many different situations, irrespective of what ship or operational conditions it is presented with. Data from many ships and voyages can be used, benefitting all participants, for example for fuel efficiency or detection of performance degradation. Operational advice can even be based on examples from the experts on board, from which RL can extract the best aspects of all and even learn to prevent mistakes.
Hannes Bogaert,
Leader AI Sail Team
Risky behaviour
Full control also means that risky behaviour can emerge. Without limiting the actions the AI can explore, undesirable behaviour can be avoided by giving proper feedback on this behaviour. This often requires the introduction of terms in the reward function that do not directly relate to the objective but serve as implicit instructions on what not to do. RL will find a balance between reaching the objective quickly and the perceived costs of the actions chosen. It might be tempting to introduce terms that describe what to do as well, but this is often too restrictive and limits exploration to find optimal actions.
Explanation of Reinforcement Learning by Fanny Rebiffé, as applied in the AI Sail project.
The algorithm was given full control of rudder, sheet and a traversing mass and the task was to sail upwind. Within the square domain the vessel could sail in, a couple of tacks was needed to reach the other side of the basin. However, with full control, some cheating is possible as well, for example by sculling: using rudder oscillations to propel the boat.
Eelco Frickel,
Team leader Time domain simulation & Data science

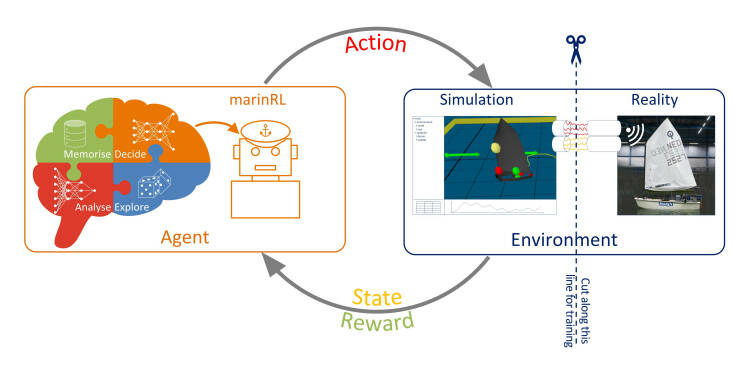
Figure 1: Connection between the AI agent and its environment. The agent does not need to know if it is dealing with a simulation or a physical environment. It sends the selected actions to the environment and receives an updated state back and intermediate feedback, thus building experience with the long-term results of actions.

The AI Sail Team consists of a broad mix of MARIN specialists including experts in AI/machine learning, time domain simulations, software engineering, sailing/wind assist and (wireless) model testing. This allowed a full-stack approach, such that AI models could be developed and pre-trained in a well-tuned simulation environment before seamlessly transitioning to the physical tests in our Offshore Basin. Being able to effortlessly combine the simulated and physical setups is invaluable for efficient development of solutions and early evaluation.
For this project a Reinforcement Learning (RL) agent was used, which learns to optimise decision processes through interactions with a dynamic environment. The optimisation is guided by so-called rewards that are given based on the current performance. The rewards mimic the sense of accomplishment when a challenging task is completed, or getting closer to completion, and reinforce the actions taken that lead to the result. Negative rewards, or penalties, can also serve as a reminder of what not to do when things go wrong. An important aspect of the RL algorithms is that they do not just connect the reward to the last actions, but rather to the series of actions that lead to a result. This is where RL differs the most from supervised learning: there is no prescribed relation between the state of the vessel and the action that needs to be taken in that state. Giving the correct feedback through rewards is not straightforward though and is often the main challenge of RL.
The background of this challenge is an important one: what can artificial intelligence and machine learning contribute to a cleaner, smarter and safer maritime world? Most maritime prediction methods are founded on a model-based approach: physics-based models are combined in a computational model and validated in tests and reality. With AI Sail we want to demonstrate the possibilities of data-driven methods, where the physics are not explicit in the model, but implicit in the data. In simple terms: if children can learn how to sail an Optimist without knowledge of aerodynamics, hydrodynamics and oceanography, an AI algorithm should be able to do the same. For a cleaner, smarter and safer maritime world, this means that predictive models or decision support systems can be brought to challenges where explicit modelling is not (fully) possible or desirable.
Put a child in an Optimist and it will learn how to sail intuitively, without understanding the details of aerodynamics and hydrodynamics. This inspired MARIN’s AI Sail Team to take up a challenge: can a computer learn to do the same with the help of AI? November 2023 was the moment of truth, during a demonstration in our Offshore Basin.
March 2024, no. 139
Create a MARIN account to stay updated
Report